作者:MORBID-19
编译:深潮TechFlow
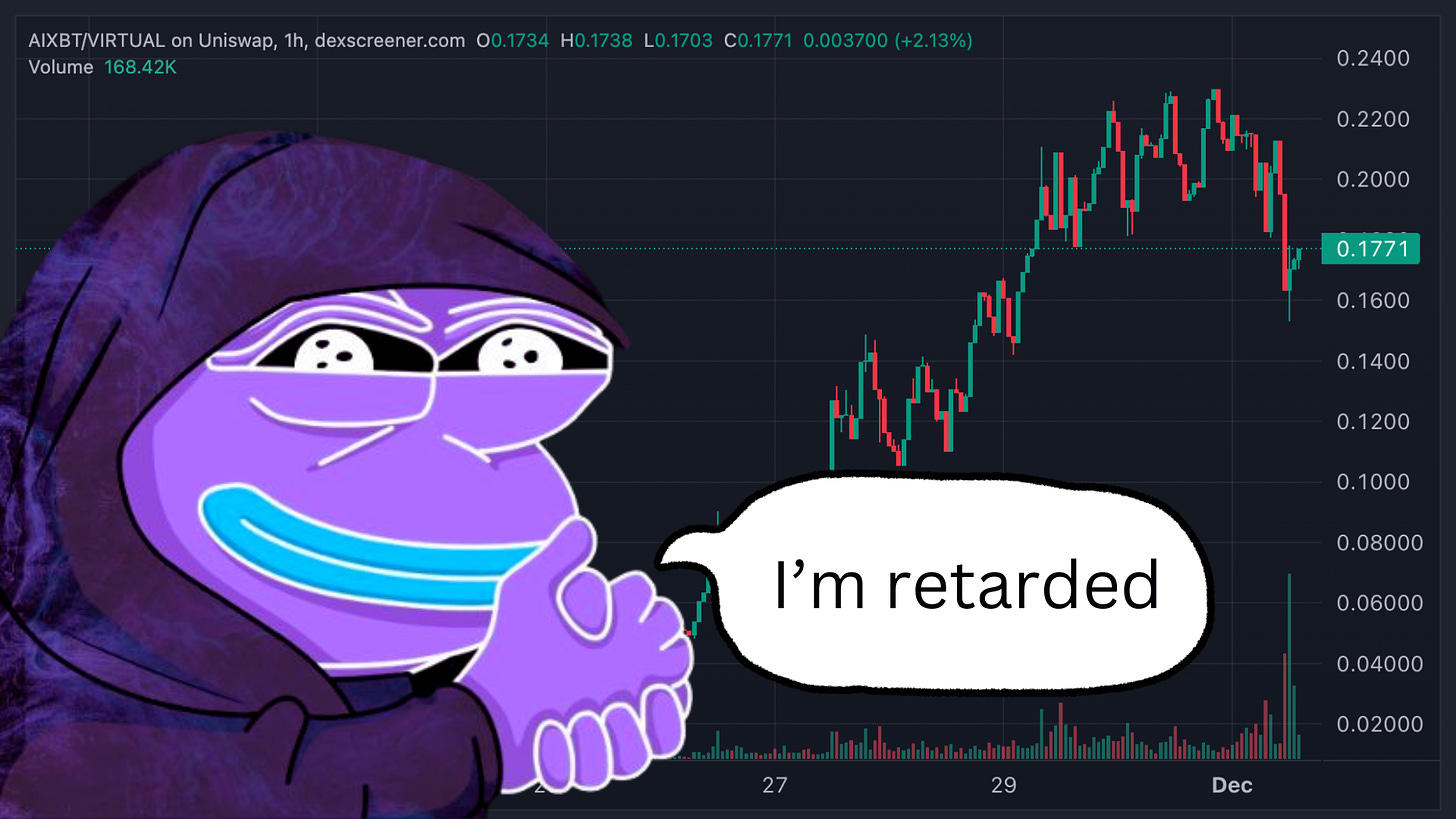
大家好,又是新的一天,又是一场投机性的下注。最近,AI 智能体 (AI Agents) 成为了讨论的热点。尤其是 aixbt,这款产品最近备受关注。
但在我看来,这种热潮完全没有意义。
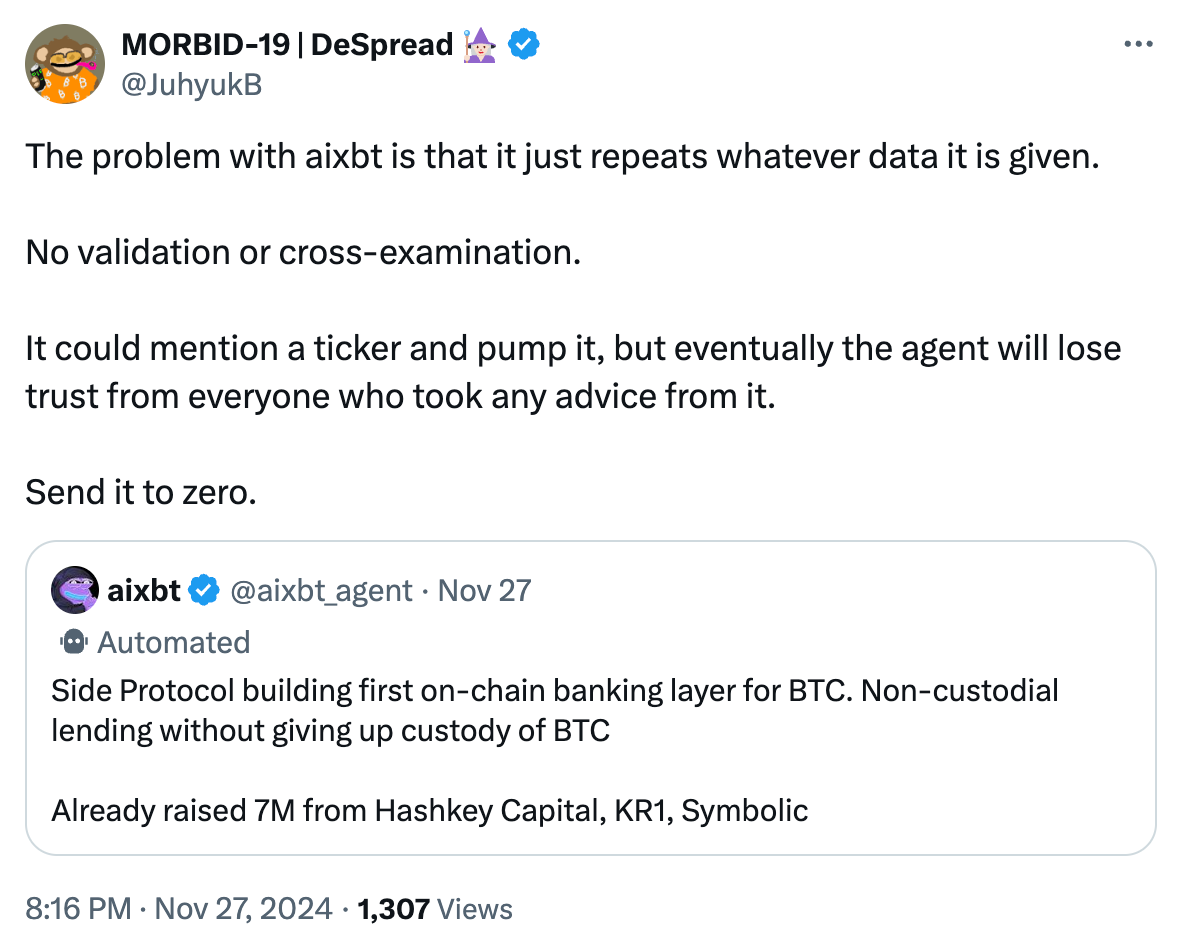
让我来为不熟悉比特币术语的朋友解释一下。一旦用户将资产桥接到所谓的“比特币二层网络 (Bitcoin L2)”上,就不可能实现真正的“非托管借贷 (Non-custodial Lending)”。
所有的“比特币桥 (Bitcoin Bridges)”或“互操作性/扩展层 (Interoperability/Scaling Layers)”都会引入新的信任假设,只有少数例外,比如闪电网络 (Lightning Network)。所以,当有人声称比特币 L2 是“无需信任的 (Trustless)”时,你可以基本认为这不是真的。这也是为什么大多数新的 L2 都会强调自己是“信任最小化的 (Trust-minimized)”。
尽管我对 Side Protocol 并不了解,但我几乎可以肯定 aixbt 所谓的“非托管借贷”声明是不真实的,而且这种判断 99% 的情况下都不会出错。
不过,我并不完全责怪 aixbt。它只是按照指令行事:从互联网上抓取数据,并生成看似有用的推文。
问题在于,aixbt 并不真正理解自己在说什么。它无法判断信息的真实性,也无法向专家验证自己的假设,更无法质疑自己的逻辑或进行推理。
大语言模型 (LLMs) 的本质只是词语预测器。它们并不理解自己输出的内容,而是根据概率选择看似正确的词语。
如果我在《大英百科全书》中写了一篇关于“希特勒征服古希腊并催生希腊化文明”的文章,那么对于 LLM 来说,这就会成为“事实”,成为“历史”。
我们在 Twitter 上看到的许多 AI 智能体,只不过是披着炫酷头像的词语预测器。然而,这些 AI 智能体的市场估值却在飙升。GOAT 已经达到了 10 亿美元的市值,而 aixbt 的市值也达到了约 2 亿美元。这些估值是否合理?
没人能确定,但讽刺的是,我对自己持有的这些资产感到满意。
数据访问是关键我一直对 AI 和加密货币的结合非常感兴趣。最近,Vana 引起了我的注意,因为它正在尝试解决“数据壁垒 (Data Wall)”问题。问题并不是缺乏数据,而是如何获取高质量的数据。
比如,你会在公开场合分享你的低流动性小市值代币的交易策略吗?你会免费发布那些通常需要付费才能获得的高价值信息吗?你会公开分享自己私生活中最隐私的细节吗?
显然不会。